
作者:乔纳森·萨尔法提
译自Creation Magazine 2018年第40卷第1期
所有生物体内都有奇妙无比的机器,还有建造这些机器的“指令手册”。正如一本书的信息是由纸上的文字记载一样,这本指令手册是由著名的DNA(脱氧核糖核酸)分子中的化学”字母”序列(核苷酸)书写。
不仅如此,这些指令还要复制到子代。其实,你并不是继承了妈妈的眼睛、爸爸的耳朵,而是再次制造妈妈眼睛和爸爸耳朵的指令被复制到了你的DNA中(参见第#页的知识窗)。
DNA物理结构带来的众多问题在最简单的生命出现之前都需要得以解决。DNA的双螺旋结构只有大概2.5纳米宽(一英寸的千万分之一)——这样的结构实在太微小,借助光学显微镜也无法观察到(一个完整的螺旋转角大概有10.5个字母的长度)。但是整条DNA分子却非常长:一号染色体是人类最大的染色体,它是由2.2亿个字母组成。如果完全展开,它的长度可达85毫米(3.4英寸)。倘若你身体某个细胞中的全部DNA都排列开来,其长度大概会到2米(6-7英尺)!这些细长黏糊的长链必须被包装在一个微小的细胞中,并要时时防止它们相互缠绕和打结而乱成一团。细胞需要复杂的机器去实现所有这些功能。而这些机器奇妙复杂,正是创造者大能的一个明证。
解开双螺旋
当DNA进行解码(用于制造蛋白质时),双螺旋结构的两条长链必须分离。在繁殖过程中,每条长链都要独立复制。
这个过程需要一种叫做DNA解旋酶的特殊马达。这种酶呈环状,中间有一个圆孔,让DNA得以穿过。但它们既然是马达,就需要燃料供应。为解旋酶供能的是一种称为ATP的“燃料”,而ATP则是从另一种马达,ATP合成酶产生的。1 在ATP的驱动下,解旋酶环上呈现波浪形变化,波速达每分钟10000转左右——这相当于飞机涡轮引擎的转速。解旋酶沿着DNA链快速运行,将DNA双链在复制叉上分离。2 之后,许多其他细胞机器会对DNA进行解码并将两条链重新粘合,或者将两条链分别复制。解旋的过程非常快,因为DNA复制速度是每秒1000个字母,解旋酶必须赶在复制机器的前边。
超螺旋
DNA螺旋状所产生的另一个问题,在解旋酶拆分长链时就凸显出来。你用一条由多股细绳扭成的绳索就容易证明这个问题:从绳索的中部开始,尝试将各股分开。没多久你就会发现各股很难拆开了,因为分离点两侧股间盘绕越来越紧,阻力增大。如果你松开绳子,它会自己重新盘绕起来——想想老式电话机的螺圈形软线,它们会很容易就层层叠叠地缠在一起。每当在解旋点的前方增加一次缠绕,解旋点后边的DNA也对称地增加一次缠绕,所以后边也变成了超螺旋结构(过度盘绕)。在细胞中,如果DNA解旋受阻,细胞就无法合成蛋白质,也不能自我复制。
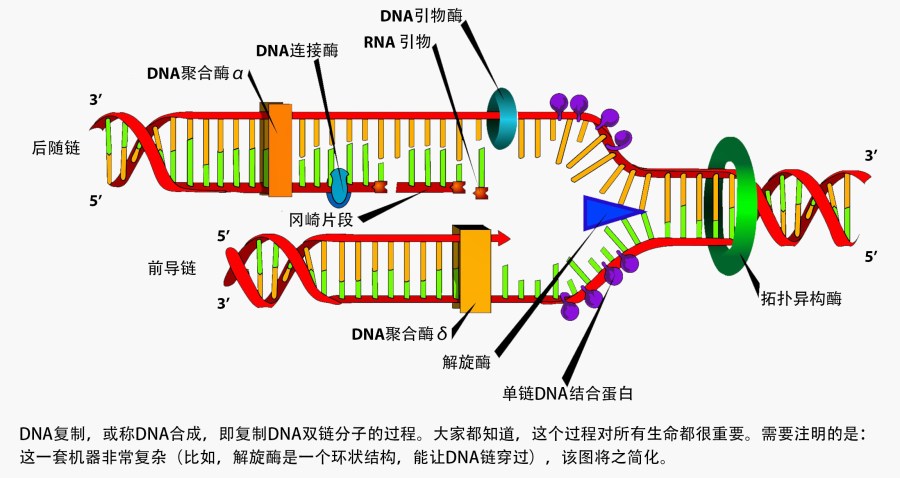
解缠机器
创造者通过一种称为拓扑异构酶3的特殊蛋白机器来解决生物体中这个问题。这种酶可以剪切DNA, 重整其结构,后再将DNA连接起来。拓扑异构酶必须赶在复制叉前方完成这些工作,避免DNA链盘绕得太紧。
拓扑异构酶有若干种,但是可以归为两大类:
- I型拓扑异构酶会把DNA双链中的一条切开,临时抓住切开的两端,让另一条没有被切的链自由穿过切口。这样就能松解双链相互盘绕拧出的张力。这一活动每进行一次会松开一个扭(即,减少一次盘绕)。最后,DNA链的剪切位点被重新连接。I类拓扑异构酶不需要ATP。它仅是让DNA盘绕过渡而积累起来的张力释放,如同松开一团拧紧的弹簧一样。
- Ⅱ型拓扑异构酶就复杂很多。这类酶会把DNA双螺旋链的双链都切开,并将切口两端分开。紧接着,它会拉着一段没有被切的DNA链穿过这个切口。之后,切口缝合。接着,它会放开刚过来的DNA链,也放开重新缝合的链条,按需要继续重复整个过程,其中有好几个步骤都需要ATP的参与。Ⅱ型拓扑异构酶之所以重要还有一个原因:当DNA进行复制时,有时候两个“子”DNA分子会像链环一样缠绕到一起。因此,将这些缠绕在一起的分子分开称为解链,这是Ⅱ型拓扑异构酶的重要功能。
除非功能齐全,否则无用
拓扑异构酶必须实现三个步骤,否则它们就无用甚至有害:剪切、拉着另一条长链穿过切口、重新连接。每一个步骤有多重要呢?如果任何一个步骤无法完成,酶就无法运作,细胞也就凋亡。
其实,某些抗菌和抗癌药物的药理也是以拓扑异构酶为标的。氟喹诺酮这类抗菌药(比如环丙沙星和左氧氟沙星)会阻挡细菌的Ⅱ型拓扑异构酶的重新连接功能,使细菌DNA的长链不断分解,从而快速杀死细菌细胞。某些抗癌药物(喜树碱和拓扑替康)也是通过同样的药理作用在癌细胞的I型和Ⅱ型拓扑异构酶上,从而令癌细胞在复制时失去控制。
另一类药物称为催化抑制剂,它能抑制ATP能量的释放,通过停止剪切(第一步)而起效。它并非把DNA分解成碎片使细胞死亡,而是让DNA缠绕在一起,令细胞既不能自我复制,也无法合成蛋白质。
进化论面临的问题
进化论认为,无机世界的随机化学反应通过逐步累积的方式产生了第一个细胞,其中的每一步都必须有进化优势,从而为自然选择所青睐。这显然是不可能的。假设该过程产生了一种酶,它可以进行第一个步骤——剪切。若然没有把长链连接起来,这只会让原来的信息分子被剪成碎片,细胞也因此受损!
但是对于进化论来说,情况比这更糟糕。自然选择根据定义就是繁殖差异:“甲种生物比乙种生物更适应环境”意味着“甲比乙有更多后代能存活下来”。因此,自然选择要求至少存在两个能自我复制的生物。说白了,自然选择无法解释复制的起源,因为在出现能复制DNA的方法之前,生物无法自我繁殖。我们也看到了,没有拓扑异构酶,DNA便无法复制,因为长链很快就互相缠绕,乱成一堆。自然选择无法解释第一个拓扑异构酶的起源,因此达尔文的进化论也就无从谈起。4
另一个问题类似于众所周知的“先有鸡还是先有蛋”。5 这个问题是:合成拓扑异构酶的指令在DNA上,但是没有拓扑异构酶去解旋DNA,这些指令便无法读取。即使最简单的Ⅱ型拓扑异构酶也是由两个蛋白质片段构成,共有800个 “字母”(氨基酸)。三个DNA“字母” 才能编码一个蛋白质字母,所以其基因内大约有2400个字母。这样的长度,没有解缠机器是无法读取的。
若然没有Ⅱ型拓扑异构酶去解开子代DNA链,这些指令也无法传递到下一代。生殖支原体的DNA在所有生物的基因组中是最简单的,但它也过于庞大,无法自我解链。
结论
就算是最简单的生物,在读取自身DNA指令以合成蛋白质或将指令传递给后代时,也需要拓扑异构酶参与。这些复杂且经过精心设计的机器能够对DNA进行剪切、移动并重新连接。没有它们参与,繁殖就无法进行。达尔文进化论——随机突变和自然选择无法产生第一个拓扑异构酶。
参考文献与注释:
- Thomas, B., ATP synthase: majestic molecular machine made by a mastermind, Creation 31(4):21-23, 2009; creation.com/atp-synthase.
- 可以从以下网址找到一个关于解开DNA双螺旋的详细说明和视频: Meet DNA helicase, evolutionnews.org, 20 February 2013. 其他优秀视频可以在DNA学习中心找到, dnalc.org.
- For more information, see DeWeese, J.E.,DNA topoisomerasesmeraseseese, J.Eand.E.,DNA top’nd.E.,DNA topois Creation 30(2):92ationtopoisoDr Joe DeWeese of Lipscomb University, Nashville, Tennessee, has published many topoisomerase papers in leading secular science journals. See also the video Topoisomerase 1 and 2, youtube.com.
- 生命起源自无机物被普遍称为化学进化。
- 根据经文,其实答案非常简单:上帝在第五日创造了鸡,然后鸡下蛋。其实,准确来说,上帝创造了鸡形目,它涵盖了大型陆地鸟类,挪亚方舟之后分化成鸡、鹧鸪、雉科鸟、鹌鹑、火鸡等等。Lightner, J., An initial estimate of avian ark kinds, Answers Research Journal 6:409–466, 2013.
DNA:最佳的信息存储系统
DNA是目前已知的最先进的信息存储/提取/传递系统。单个活细胞中的DNA信息密度大概为每立方毫米1000兆字节(1000TB)。1 所以它可以在一个非常小的空间内存储巨量信息:最简单的生物要数支原体(Mycoplasma),它寄生于细胞内,其DNA信息量大概是60万字节(600KB),而单个人体细胞的DNA信息量大概为3G。2
如果将单个人体细胞的信息用纸张和墨水写下来,大概需要1000本圣经大小的书(或200部美国税法)。3 值得注意,信息并非来自书页上墨水的化学属性——并非把墨水泼洒在纸上,这些信息就会出现。作者将墨水组织成字母,信息才会出现。同样,DNA“字母”的化学属性与生命信息是两码事。
参考文献与注释:
- 可以从下面网址找到更多细节和文献资料Sarfati, J., DNA: the best information storage system, 9 October 2015; creation.com/dna-best. See also Batten, D., DNA repair mechanisms ‘shout’ creation, Creation 38(2):56, 2016; creation.com/dna-repair.
- 为了简化问题,我把每个DNA“字母”比成一“字节”的信息,实际也差不多。事实上,每个核苷酸位点有四种可能性,我们可以用两个字节储存一个字母,这样可以把总内存需求降低4倍。然而,若是一个字节对应一个字母,我们的基因组有31.7亿个碱基对(bp),每个细胞中有两套基因组拷贝,即63.4亿个碱基对,那就是5.90 GB。
- Erb, K.E., [American] Tax code hits nearly 4 million words, Taxpayer Advocate calls it too complicated, forbes.com, 10 January 2013. For comparison, the KJV has almost 800,000 words. 美国税法有将近400万字,英文钦定本圣经有将近80万字。
